Induction de lexiques sémantiques pour l’interprétabilité et la diversité en traitement de textes
-
Projet financé par l’Agence Nationale de la Recherche - ANR
Le deep learning constitue une révolution majeure en intelligence artificielle dans de nombreux domaines, et le traitement automatique des langues (TAL) n’y échappe pas. Des modèles de langue tels que BERT et GPT-3 font désormais la une des journaux grâce à des performances similaires voire meilleures que celles des humains dans des tâches complexes telles que la génération et la compréhension de textes.
Cependant, l’enthousiasme actuel pour les modèles de deep learning en TAL rencontre des limites. Premièrement, l’opacité de ces modèles rend leur interprétation très difficile. Ils sont composés de millions de fonctions mathématiques avec des milliards de paramètres numériques, le tout optimisé automatiquement sur des tonnes de données. Cela les rend très opaques, si bien qu’expliquer leurs “décisions” est devenu un thème de recherche à part entière.
Deuxièmement, ces modèles sont souvent évalués sur des jeux de test fixes et bien connus (benchmarks). Leurs performances sont affichées sur des leaderboards et sont des arguments de compétitivité pour les entreprises qui les développent. Mais ce type d’évaluation passe sous silence certains biais et questionne la robustesse des généralisations apprises. De plus, la plupart des modèles sont fondés sur les mots et ignorent les expressions (p.ex. avoir du pain sur la planche n’a rien à voir avec l’emplacement d’une baguette).
L’idée du projet consiste à apprendre à partir de grands volumes de texte un lexique sémantique, en combinant des représentations contextuelles continues (embeddings) issues des modèles de deep learning avec des représentations symboliques et donc interprétables (étiquettes). Cela s’effectuera à l’aide du clustering d’occurrences de (multi-)mots en sens, puis des sens en cadres sémantiques (groupes de sens similaires), auxquels seront associées des structures argumentales, comme montré dans la figure ci-dessous:
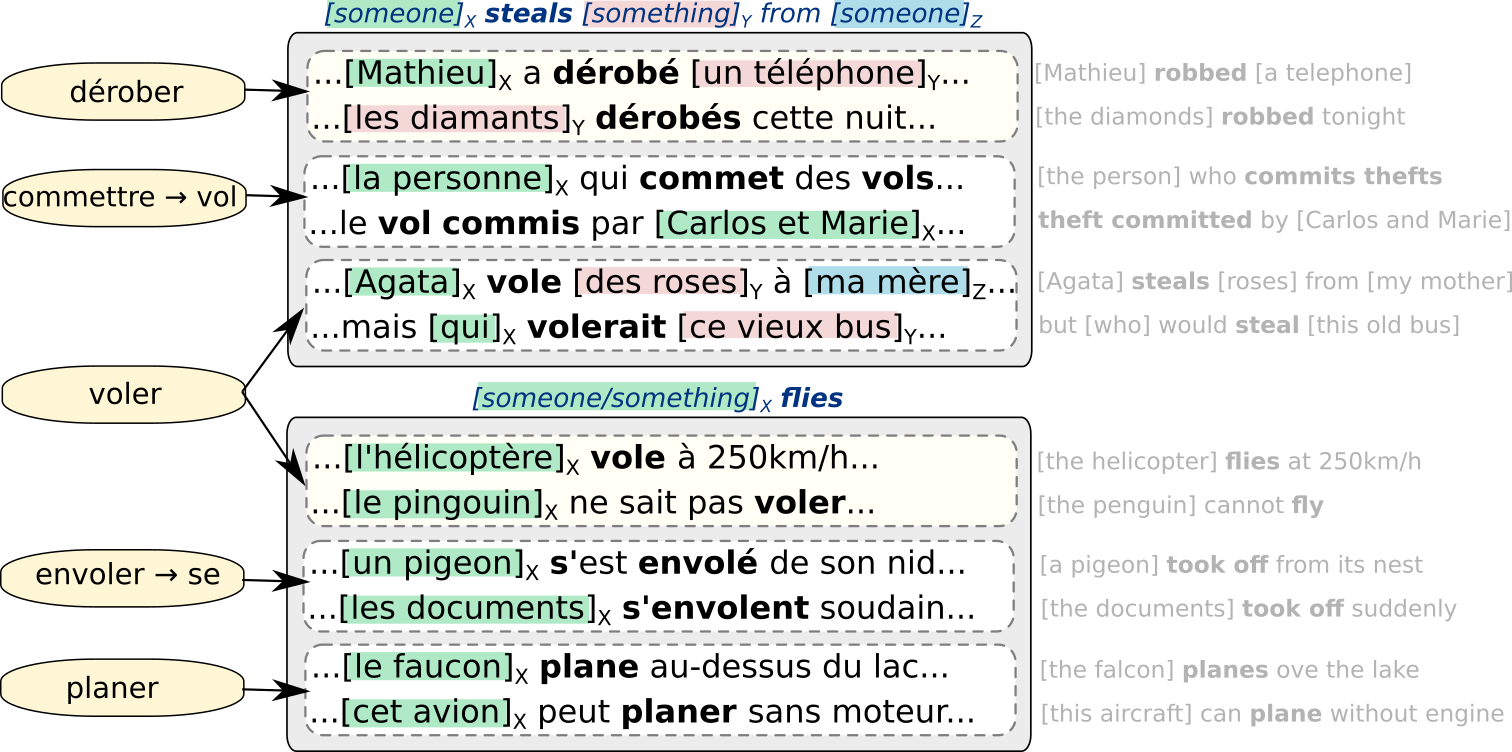
L’évaluation du lexique se fera en l’intégrant dans des modèles existants d’analyse sémantique et de compréhension de textes. Le but est de mesurer si une pré-structuration en lexique améliore ces tâches aval, favorise l’interprétabilité des décisions, et augmente la diversité des phénomènes couverts, en particulier des éléments rares ou non vus dans les corpus d’entraînement. À long terme, ce lexique et les méthodes développées pour l’apprendre constituent une façon alternative d’aborder la question du sens, ni trop rigide comme dans les modèles symboliques traditionnels, ni trop obscure comme dans les systèmes deep actuels.
Pour en savoir plus, lisez la proposition détaillée du projet (PDF, en anglais).