SEmantic LEXicon INduction for Interpretability and diversity in text processing
-
Project funded by Agence Nationale de la Recherche - ANR (2022 – 2026)
Deep learning represents a major revolution in many fields of artificial intelligence, and natural language processing (NLP) is no exception. Large pre-trained language models such as BERT and GPT-3 made it to the newspaper headlines, thanks to performances that are similar if not better than that of humans in complex tasks such as text generation and comprehension.
However, today’s enthusiasm for deep learning models in NLP seems to be reaching its limits. First, the opacity of these language models makes their interpretation very difficult. They are made up of millions of mathematical functions with billions of numerical parameters, all of them automatically optimised on tons of data. In practice, they are often black boxes so that explaining their predictions has given birth to a whole new research topic in NLP.
Second, these models are often evaluated on well-known stable benchmarks. Their performances are displayed on leaderboards, becoming competitiveness arguments for the companies that develop them. Though, this kind of evaluation ignores certain biases and questions the robustness of the generalisations learnt. On top of that, most models are based on words or sub-word units, ignoring non-compositional multiword expressions (e.g. a hard nut to crack has nothing to do with one’s skills to use a nutcracker).
The SELEXINI project proposes to address opacity and robustness issues in language technology via the notion of a hybrid semantic lexicon. Our goal is to automatically induce semantic lexicons from very large text bases. We combine continuous contextual representations (embeddings) stemming from neural language models with symbolic interpretable representations (labels). The idea is to develop semi-supervised clustering techniques to group (multi-)word occurrences into senses, then senses into semantic frames (groups of senses that share similar semantics), which are in turn associated with their argument structures, as shown in the schema below:
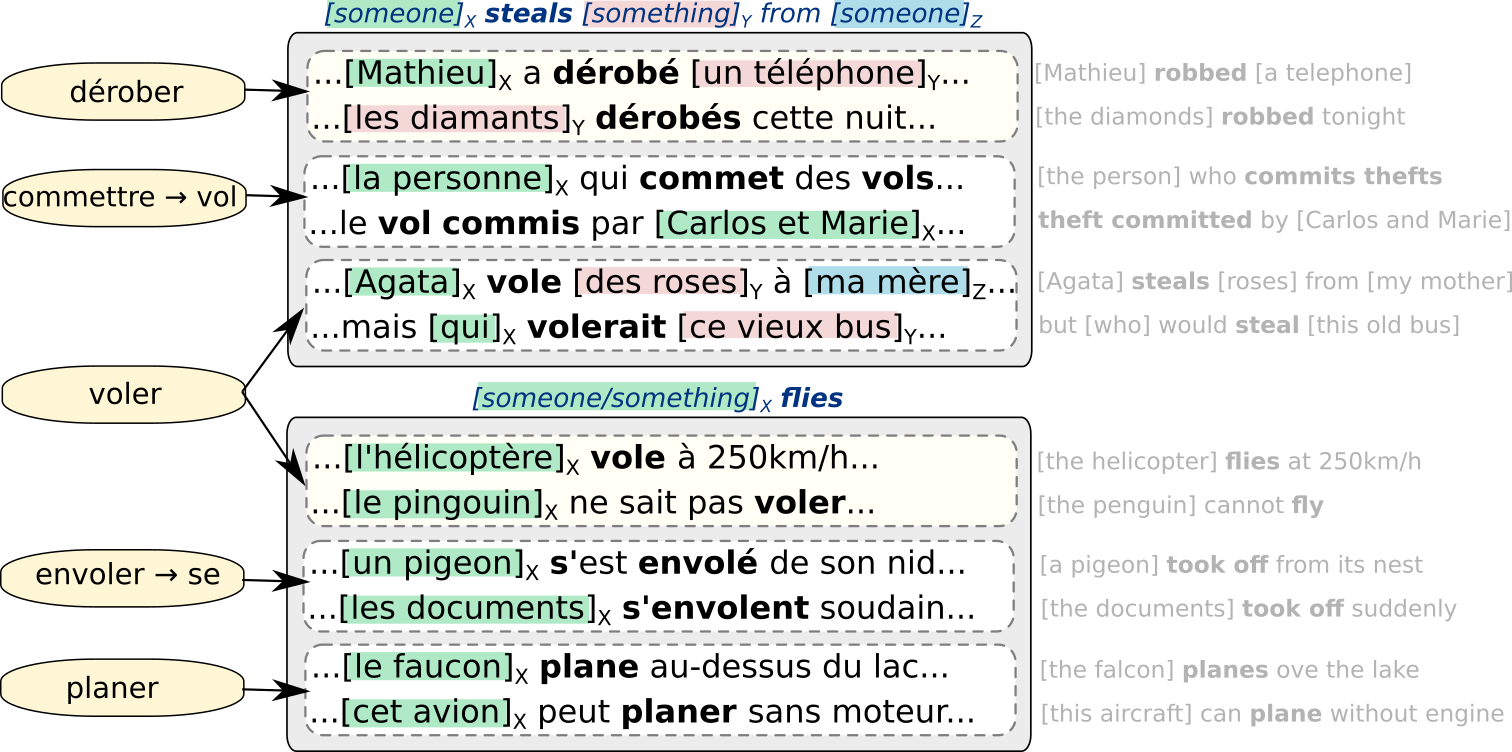
The induced lexicon will be integrated into existing natural language understanding systems. Thus, we will assess to what extent the abstraction and pre-structuration provided by the lexicon can improve the existing systems, favouring the interpretation of the system’s answers and increasing the linguistic diversity of inputs taken into account, especially in zero-shot and few-shot scenarios. We expect that the SELEXINI lexicon and the methods developed to learn it may give rise an alternative way to approach the question of meaning representations: not too rigid as in traditional formal models, nor too obscure as in modern deep learning systems.
Want to know more? Check out our full project description - grant application (in PDF).